Motivation
As a security researcher, adopting a holistic approach could lead to finding unexpected vulnerabilities. You start with something but end up with something more interesting. Recently this happened to me and I wanted to share my research approach which could be easily applied elsewhere.
In this case, I was chasing a blind SSRF vulnerability and was rabbit-holed into a URI parser bug.
Background
Blind SSRF vulnerabilities arise when an application can be induced to issue a back-end HTTP request to a supplied URL, but the response from the back-end request is not returned in the application’s front-end response.[1]
If you have identified a blind SSRF thats leads you no where, there are still some interesting things which could be identified. The most basic of it would be the User-Agent String hitting your endpoint. Some others include sensitive API keys, cloud storage keys and GET parameters, all of which could be used in further attacks.
For this post, we will focus on how this User-Agent string led me to identify a bug in the URI parser itself.
Approach
Once the SSRF endpoint was identified, a request was made to the Burp collaborator client [2], indicating a successful out-of-band interaction:
GET / HTTP/1.1
Accept: application/octet-stream, image/jpeg
Content-Type: image/jpeg
x-b3-traceid: [omitted]
x-b3-spanid: [omitted]
x-b3-parentspanid: [omitted]
x-b3-sampled: 1
Host: [omitted].burpcollaborator.net
Connection: Keep-Alive
User-Agent: Apache-HttpClient/4.5.2 (Java 1.5 minimum; Java/11.0.5)
Accept-Encoding: gzip,deflate
Looking at the above, our first instinct would be to investigate the x-b3-* headers. But nothing interesting there, These headers are used for trace context propagation across service boundaries [3]
The next thing to look for was weather the server actually honored the Accept and Content-Type HTTP headers. It looked like it did not i .e. it expected an image but you can send it anything and the server would accept it. After that, the application would send it through some image processing library server-side and would error out. Also, that library accepted only JPEG files. (not even PNG!) This is an interesting scenario in itself but it was a dead-end in this case - worth a note.
Looking back at the User-Agent string, its pretty obvious that the client is Apache HttpClient with that particular version plus the JVM version as well. So I downloaded this version of HttpClient and setup a project in eclipse to investigate how the URL is being parsed and weather the Accept headers are even required. Researching URI bugs and Path normalization issues, I recalled a great piece at Black Hat by Orange Tsai [4] and it gave me some direction - if I can try to send some ambiguous URI, it might help me in the above blind SSRF. The Tangled Web (book) is another great resource which talks at length about URI parsing[5]
After a bit of research, I concluded that majority of the bugs should be in the authority and path components

So coming back to the parsing, RFC3986/RFC2396 is the official guidance so to quote Section 3.2 from it -
The authority component is preceded by a double slash “//” and is terminated by the next slash “/”, question-mark “?”, or by the end of the URI. Within the authority component, the characters “;”, “:”, “@”, “?”, and “/” are reserved.
Playing with some payloads, it was concluded that the following should resolve to google.com, but the Apache Httpclient resolved to apache.org:
http://user@apache.org:80@google.com/
Before we find out the root cause, lets verify our assumption in the latest version of the Firefox browser:
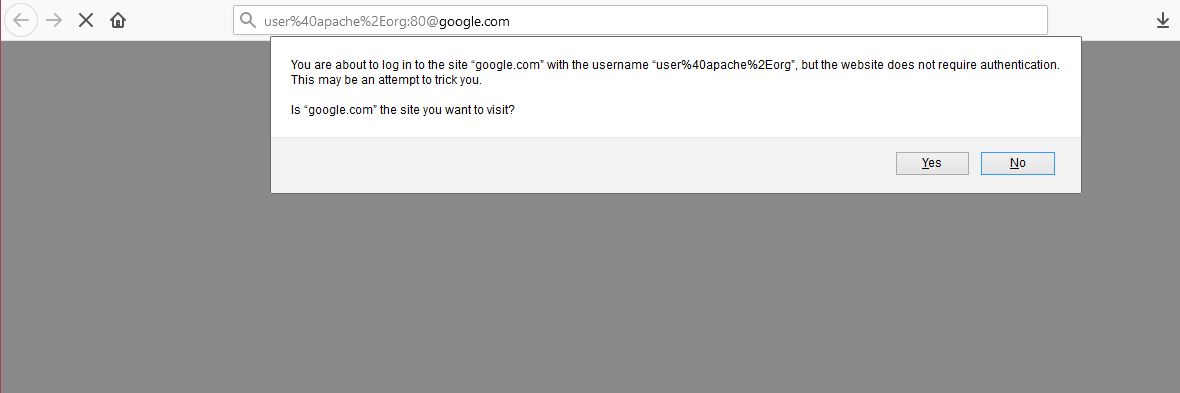
All right, Check.
Lets verify it in python?
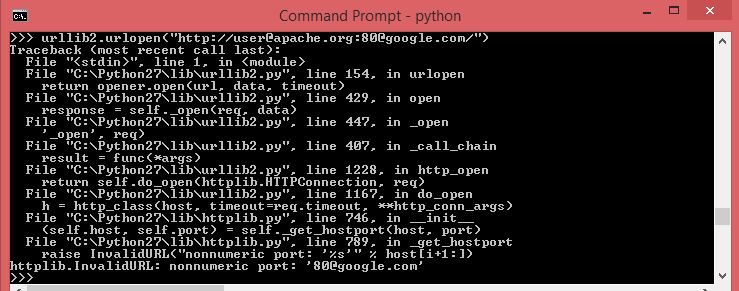
So clearly there is a mis-match in URI Parsing implementations.
Investigating the root cause
I traced the entry point and implemented a proof of concept by calling the request object with the following (Omitted the non-relevant snippets for brevity):
1: CloseableHttpClient httpclient = HttpClients.createDefault();
2: HttpGet request = new HttpGet("http://user@apache.org:80@google.com/");
3: CloseableHttpResponse response = httpclient.execute(request).
Stepping in through debugger in Eclipse, at line 2, when HttpGet() parses the URI, it ultimately calls java.net.URI which returns the host as null, but URIUtils::extractHost() still attempts to incorrectly parse it - “http://user@apache.org:80@google.com/” -> apache.org
At this point, the call trace looks like this:
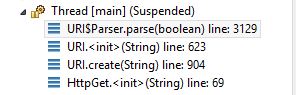
Tracing further, CloseableHttpClient::determineTarget() is called which in turn calls URIUtils.extractHost(requestURI):
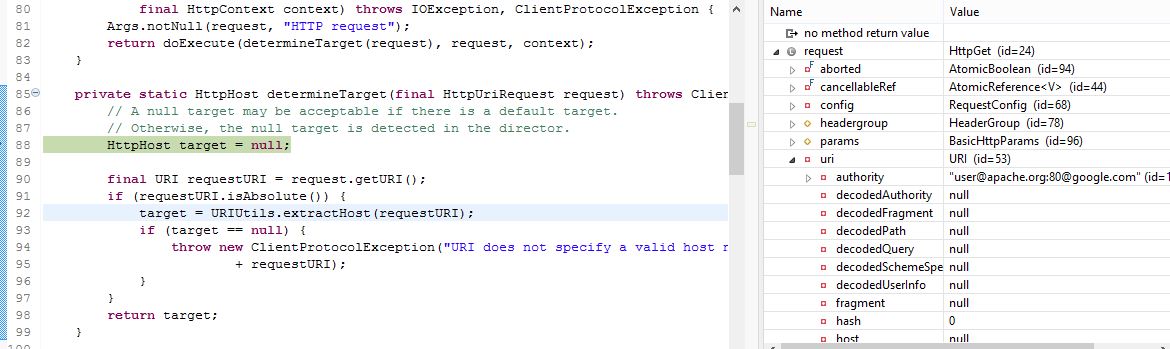
Stepping further, we conclude that this is the culprit method - URIUtils::extractHost():
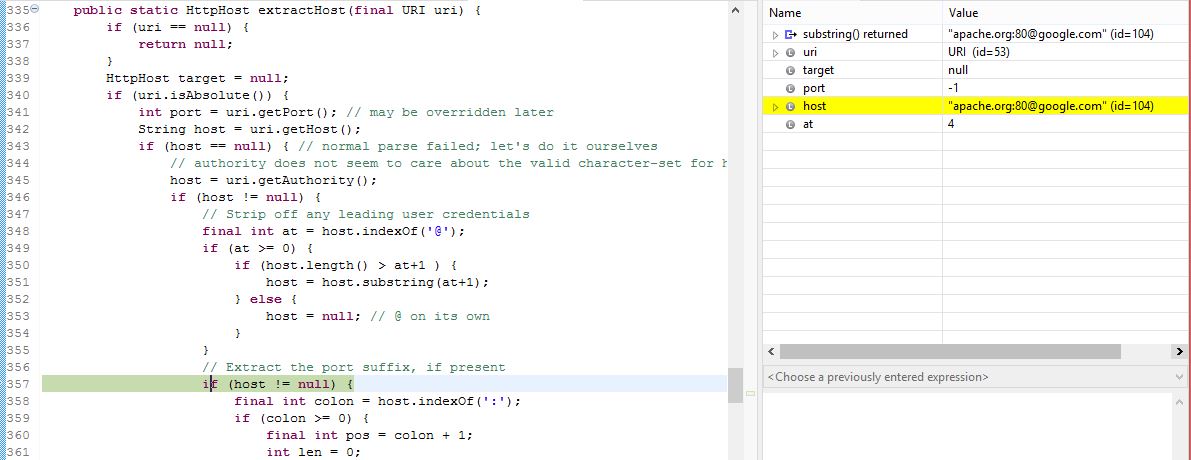
Lets look at the code as to why:
249: public static HttpHost extractHost(final URI uri) {
250: if (uri == null) {
251: return null;
252: }
253: HttpHost target = null;
254: if (uri.isAbsolute()) {
255: int port = uri.getPort(); // may be overridden later
256: String host = uri.getHost();
257: if (host == null) { // normal parse failed; let's do it ourselves
258: // authority does not seem to care about the valid character-set for host names
259: host = uri.getAuthority();
260: if (host != null) {
261: // Strip off any leading user credentials
262: final int at = host.indexOf('@');
263: if (at >= 0) {
264: if (host.length() > at+1 ) {
265: host = host.substring(at+1); //After fetching the authority, the first '@' should be read from the far end and not the beginning.
266: } else {
267: host = null; // @ on its own
268: }
269: }
270: // Extract the port suffix, if present
271: if (host != null) {
280: final int colon = host.indexOf(':');
At line 256, after the uri.gethost() fails, the implementation attempts to parse the host. However, after fetching the authority, the first ‘@’ should be read from the far end and not the beginning - The parsing logic is inconsistent with RFC3986/RFC2396 spec. At this point, either the imnplementation should either error out or give us the correct hostname i.e. google.com.
After figuring out the root cause, I promptly reported to the Apache security team who in turn quickly acknowleged it and fixed it in version 4.5.13 and 5.0.3 respectively. [6]
This issue was also assigned CVE-2020-13956 [7]
If you are wondering about the blind SSRF, sadly that didn’t lead me anywhere - well, thats the nature of security research.
References:
- [1] https://portswigger.net/web-security/ssrf/blind
- [2] https://portswigger.net/burp/documentation/desktop/tools/collaborator-client
- [3] https://github.com/openzipkin/b3-propagation
- [4] https://www.blackhat.com/docs/us-17/thursday/us-17-Tsai-A-New-Era-Of-SSRF-Exploiting-URL-Parser-In-Trending-Programming-Languages.pdf
- [5] https://nostarch.com/tangledweb
- [6] https://github.com/apache/httpcomponents-client/commit/60f8edb242aa3f868098512cd9559b8846a3d44c
- [7] https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-13956